Scrum by Example - How to Handle Production Support Issues in Scrum
Last Updated: May 2025

Whenever you are building and deploying a complex system, there are always going to be bugs, defects, and unforeseen problems with usability — commonly referred to as Production Support issues. Today, our ScrumMaster and their Team grapple with these issues, to help you understand how they affect a Scrum Team and what you can do to prevent them from dragging you down.
Dramatis Personae
Steve: A ScrumMaster and the hero of our story
Paula: The Product Owner of Steve’s team
ScrumMaster Steve and his Team have released the World’s Smallest Online Bookstore. It’s live, and books are selling and shipping. This turns out to be a blessing and a curse because the business is making money, but with it comes support issues.
In the first two Sprints after the release, the Team noticeably struggles and often fails to meet its planning commitments. At first, Steve is okay with this, believing it’s inevitable post-release hiccups but, when it’s clear that the trend is continuing into the third Sprint, he starts to get worried. He spends some time watching the Development Team work and notices that Team members are often interrupted several times a day. Most of these interruptions are from production support issues.
When an application is deployed to a live site or system, the system users will inevitably find defects, ways to use it that the development team hadn’t intended, and other small issues. Most organizations that run these kinds of systems have helpdesks for users to raise these issues with.
At the company developing the World’s Smallest Online Bookstore, they have a chronically understaffed helpdesk group who provides two lines of support. They primarily respond to and resolve customer queries, known as first-line support. When an issue can’t be resolved with a simple phone call, chat, or email, they investigate to see if the problem is a defect or the platform being used in unexpected ways, known as second-line support.
It is this second line support that is causing frequent interruptions, as whenever they find a defect or usability issue, they submit a production support ticket to Steve’s Team. To document this, Steve adds a “swimlane” at the bottom of the Team’s Sprint Backlog board, labelled “Production Support and Other Interruptions.”
After four or five Sprints, he charts the resulting effect on the Team’s Sprint Burnup (Burndowns and Cumulative Flow Diagrams could be used as well), to show the correlation between Production Support Issues each Sprint and the number of Backlog Items completed.
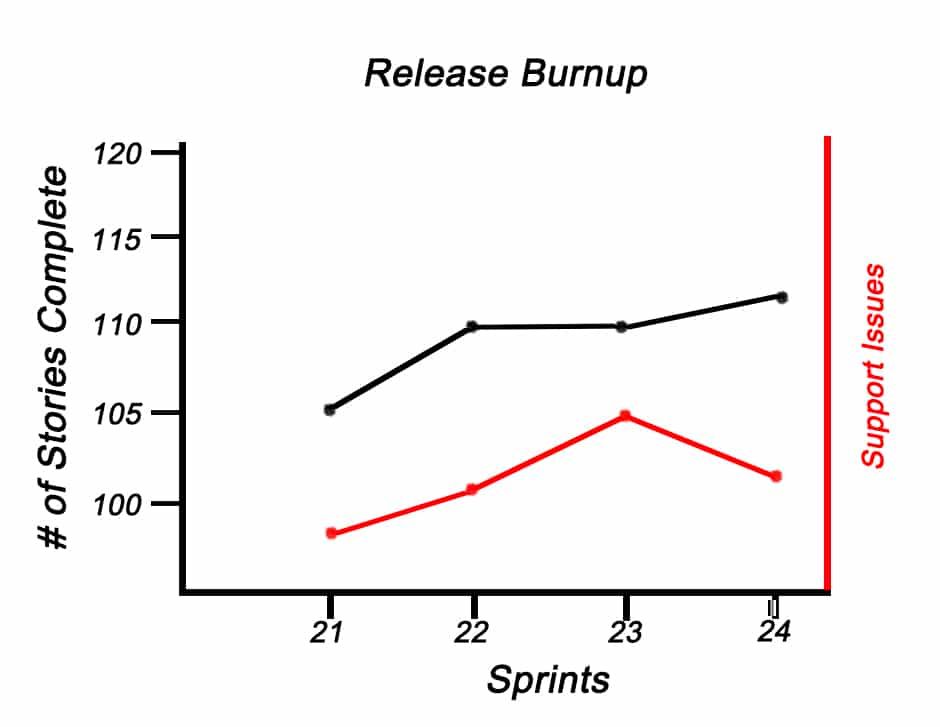
During the next retrospective, Steve chooses a timeline to help the Team review what has happened.1 He also uses the data from the burnup chart to help them see the resulting effects. They discover that it’s even worse than Steve realized - Team members aren’t just being interrupted, they’re spending most of their time handling support issues.
How to stop production support issues from disrupting the Team
The first line of defence, before the Team even sees a support issue, is the Product Owner. Paula should take a look at a support issue first, then ask herself, “Is this problem worth interrupting the Team during this Sprint?” If the issue, or even a defect, isn’t absolutely critical to delivering value to the customer, it may be best addressed by adding it to the Product Backlog and asking the Team to address it as a User Story in a later Sprint.
The Team can also do a number of things to mitigate interruptions:
- Choose one Team member each Sprint who will become the primary point of contact for support issues. This member would involve others on the Team as needed. This job should rotate, so it’s not always the same person. Note: I have, on occasion, called this “Rotating One Victim Per Sprint Strategy.”
- If working with multiple Teams, in any one Sprint have one Team handle all production support work. Each Sprint the Team doing the work changes.
- Wait until the end of the workday before interrupting another Team member for help on a support issue.
- Monitor production support issues and track their effects on the Team’s productivity. I.e. in the days following the resolution of a support issue, measure the cost of fixing the issue in terms of fewer User Stories completed, but also in associated costs, such as time deploying fixes and effects of multitasking on productivity.
- Based on historical needs, acknowledge in planning that there is a “tax” of 20-30% of Team capacity needed for production support. Note: This is my least favourite solution because it doesn’t help make the situation better, it just increases the Team’s awareness of it.
- Extreme version of this solution is Pattern: Illegitimus Non Interruptus – cancel the Sprint if interruptions exceed the timebox. Note: This works well to highlight the problem, however, I would only recommend it as a last resort.
- Limit the number of production support items “in Progress” to one. This forces hard decisions to be made about the value of fixing an item immediately but limits the ability to fix another one before the first is finished.
The obvious problem is that these defects detract from the Team’s ability to finish User Stories in a Sprint. However, the problem is much deeper than just that. When any interruption happens in a Sprint, the Team loses focus. When they lose focus, it harms the quality of the work they were doing on the new Stories.
Handling emergency defects in Sprint leads to fewer completed Stories, more defects in those Stories, and poorer quality fixes to defects as people rush. Which, at a later date, will cause more interruptions in the Sprint. In Systems Thinking this is called a negatively reinforcing feedback loop.
These band-aid solutions help the Team keep going, minimizing harm, but they fail to address the systemic issue. In any environment where a problem occurs, there are always going to be multiple and interrelated causes and effects – there is never just one root cause or single source of problems.
“In accident investigation, as in most other human endeavours, we fall prey to the What-You-Look-For-Is-What-You-Find or WYLFIWYF principle. This is a simple recognition of the fact that assumptions about what we are going to see (What-You-Look-For), to a large extent will determine what we actually observe (What-You-Find).”2
Instead of finding causes and eliminating problems – which suffers from hindsight bias3 – everything is clear looking back. We run experiments that we hypothesize will improve the situation (Unit Testing, Test-Driven Development, Behaviour-Driven Development) and look to see if the data from these experiments supports this outcome.
However, to permanently solve the problem requires a mindset change. In a real-world example, groups at Microsoft have done this by targeting Zero Defects.4 By making defects the exception and not the norm, people start building habits earlier to avoid them altogether. You will never get to zero, but you should find changing the mindset around defects has a radical effect on quality.
Small changes can overcome big, systemic problems
It took the Team over 20 Sprints (almost an entire year) to get to this state, so they’re not going to resolve this problem in a few Sprints. Steve, knowing this is going take a long time for the Team to grow past, suggests that the Team make a few small commitments during the next Retrospective that they think will help. The Team decide:
- There is a limit of one Production Support issue worked on at one time. When these are being worked on, at least two members work together pair program to find the simplest fix.
- All new code has acceptance tests written for it at the time it is created.
- When Production Support Issues are found, an acceptance test is created that demonstrates the defect.
- They set a goal every Sprint of having zero net new defects, agreeing to drop Stories rather than push new defects out of the door.
This a good start to turning the quality issues around. Six months later we check back in with the Team – they have reduced their support workload to ~20% of the time (still not great, but a far cry from the 50%+ they had before), they have slowed down, and with renewed focus on quality are finally delivering on zero net new bugs every Sprint. The original goal of Acceptance Tests for all new code wasn’t achieved in the first few Sprints after it was suggested. It took the better part of the next two months, but they would eventually get there.
Scrum by Example is a narrative-style blog series designed to help people new to Scrum, especially new ScrumMasters. If you are new to the series, we recommend you check out the introduction to learn more about the series and discover other helpful articles.
Do you want to coach your team towards better solutions?
The above scenario, and others experienced by our well-intentioned but often misguided fictional ScrumMaster Steve and Team, are topics commonly discussed in our training workshops. Fundamentally changing the way a Team works as it transitions to practicing Scrum is one of the more challenging issues that organizations face in their Scrum evolution. We would love to have you join us to receive hands-on learning of the challenges – and solutions – as well as tips on how to integrate them into your Scrum.
Image attribution: Agile Pain Relief Consulting (Updated March 2025)
Footnotes
-
Most Sprint Retrospectives focus on the current Sprint, however, it does help from time to time to have a retrospective with a wider remit. ↩
-
The ETTO Principle: Efficiency-Thoroughness Trade-Off: Why Things That Go Right Sometimes Go Wrong by Erik Hollnagel https://www.amazon.ca/ETTO-Principle-Efficiency-Thoroughness-Trade-Off-Sometimes-ebook/dp/B077315CYY/&tag=notesfromatoo-20 ↩
-
Hindsight Bias https://en.wikipedia.org/wiki/Hindsight_bias ↩
-
Microsoft - No Bugs Journey https://docs.microsoft.com/en-gb/archive/blogs/ericgu/no-bugs-journey-episode-2-its-a-matter-of-values ↩

Mark Levison
Mark Levison has been helping Scrum teams and organizations with Agile, Scrum and Kanban style approaches since 2001. From certified scrum master training to custom Agile courses, he has helped well over 8,000 individuals, earning him respect and top rated reviews as one of the pioneers within the industry, as well as a raft of certifications from the ScrumAlliance. Mark has been a speaker at various Agile Conferences for more than 20 years, and is a published Scrum author with eBooks as well as articles on InfoQ.com, ScrumAlliance.org and AgileAlliance.org.



