Scrum Anti-Patterns: The Hardening Sprint
Last Updated: May 2025
Hardening Sprints are one of the most common kinds of Scrum Anti-Patterns: ways of addressing recurring problems that seem like effective solutions at the time but in fact hamper productivity or create more problems later on. Here we introduce why they are used, why they are not an effective design pattern, and how you can create more effective solutions.

In software development work, a design pattern is a description of a solution to a recurring problem. It outlines the elements that are necessary to solve the problem, including context and the consequences of certain actions, without prompting the reader to solve the problem a specific way, leaving them with the agency to write code as they see fit. Patterns, when applied well and not overused, provide a guide to solving repetitive problems rapidly. A good pattern provides enough background information to help the reader appreciate where it is applicable, without declaring that is the best solution in all instances.
Scrum, Agile, and Kanban, in this sense, are sets of behavioural design patterns. In the Scrum Community, we have Scrum PLOP (Pattern Language of Programs) that documents known patterns of effective behaviour.
Unfortunately, we also regularly see recurring patterns of ineffective behaviour. These are called Anti-Patterns.
“An anti-pattern is just like a pattern, except that instead of a solution it gives something that looks superficially like a solution but isn’t one.” ~ Andrew Koenig1
To explore the topic more deeply, please see this growing collection of articles.

](/blog/category/anti-patterns/)
Scrum as an approach is already designed to deal with the unpredictable, without having to force exceptions. Whenever a team creates an exception, such as a special Sprint to solve a challenge, it creates an Anti-Pattern, which often results in additional problems.
The following is an exploration of one of the most common Anti-Patterns: the “Hardening Sprint.”
Anti-Pattern2 Name: Hardening Sprint
Aliases: Stabilization, Hangover, Release Sprint, or IP Iteration (Innovation and Planning Iteration in SAFe)
Scale: Team and across multiple teams
Related Anti-Patterns: Sprint 0, Separate Test Team; Component Teams; Technical Debt can be paid off later; Sprint Burndown Charts, Velocity is Important, ….
Potential Solutions:
- Better Definition of “Done”
- Improve Engineering Practices
- Slowdown
Why a Hardening Sprint might seem like a good idea
Teams new to Scrum often focus on getting as many User Stories finished as they can every Sprint. If they have good discipline, they write Unit Tests for their code. Once complete, they ship the feature off to their overburdened testers. In Sprint Review, the feature is accepted by the Product Owner. If defects are found, they’re added to the Product Backlog in a lower priority slot.
While this sounds fine on the surface, trouble may be brewing. If they finish User Stories to the Definition of “Done” but that definition still leaves some things to be dealt with later, eventually it’s going to catch up to them.
After five or six Sprints at this pace, they may elect to pause and have a “special” Sprint, or Hardening Sprint. They use this Sprint to do all of the work that they postponed during the working Sprints. The delayed work often includes tasks such as running a regression test suite, doing performance tests, and fixing defects. Often more defects are found than can be fixed. Once the Hardening Sprint is complete, the Product is released to Production.
While this is common practice, it’s not in the spirit of Scrum. Scrum is intended to help teams learn the rigour and discipline to ship working software at the end of every Sprint. Clearly, having a Hardening Sprint as part of this process allows the Team to avoid dealing with that challenge, therefore becoming an anti-pattern.
Teams who have spent a long time working in a waterfall fashion often elect for Hardening Sprints. This isn’t surprising since Hardening Sprints seem like a logical replacement for the testing and deployment phases they’ve been used to. But that’s only because Teams new to Scrum haven’t yet felt the pain that is caused by these special Sprints, so they’re more likely to fall into the trap of thinking they’re the solution to the difficult question of how to deliver working software at the end of every Sprint.
Consequences of using Hardening Sprints
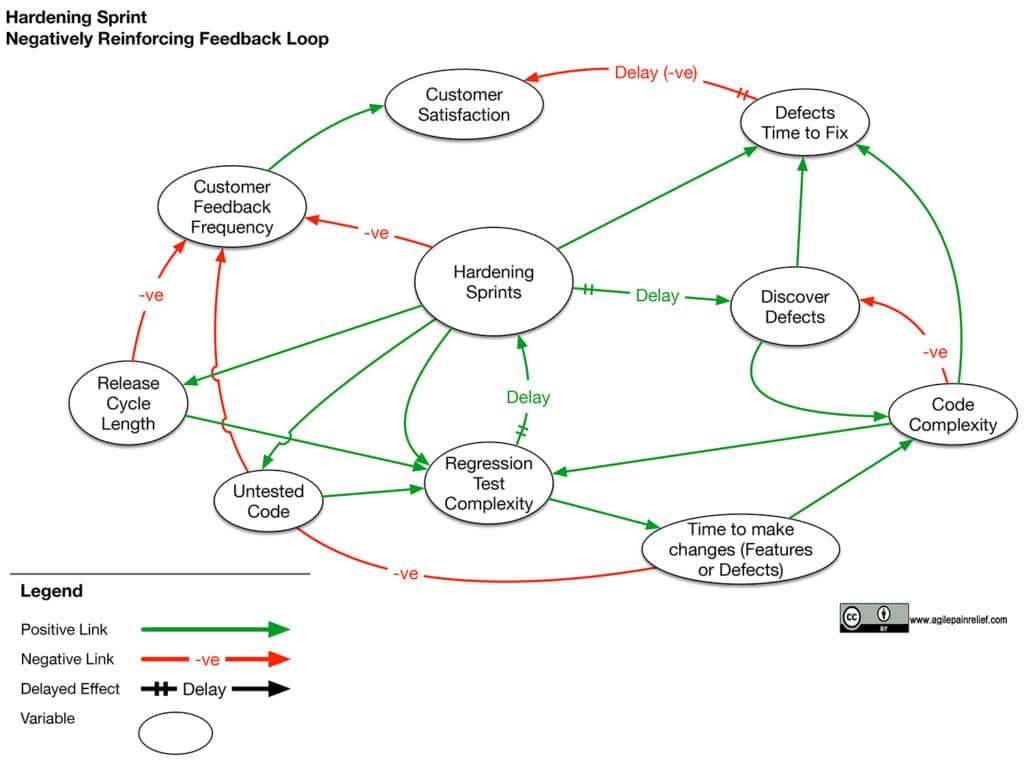
Hardening Sprints are essentially the Scrum developers’ version of “we’ll fix it in post.” They tend to decrease the readability of the code base because people have a habit3 of delaying any tidy-up work until then. The messier the code is to read, the harder and more time-intensive it is to add new features or test existing ones. Many people call this Technical Debt.4 It doesn’t take long before the team needs to add more time into the Hardening Sprint to get the work fully tested.
Hardening Sprints have negative downstream consequences too. By delaying the release of a working product to the customer, we delay when they will pay us. Conventional or Waterfall approaches to product development delay tasks like testing and writing documentation to the end of the development process. When we delay work until a Hardening Sprint, we’re dragging a waterfall approach into an Agile environment.
The use of Hardening Sprints leads to:
- A larger volume of untested code – Many forms of testing (regression, performance, usability, etc.) are postponed until the Hardening Sprint.
- Defects difficult to resolve – The longer we delay in fixing them, the harder they are to fix, both because the person who wrote them forgot their intention and code base will have evolved so we may be relying on the defective behaviour elsewhere.
- An increase in defects that are either not discovered or discovered later – The more time that passes between writing code and testing it, the harder the defects are to find. In many cases, because of the ever-growing complexity, the defects are never found.
- Delay for the customer – In real Scrum, the customer can use the Product Increment (aka Working Software) at the end of every Sprint. With Hardening Sprints, they get access only after the Hardening Sprint. If Hardening Sprints happen every 5-6 Sprints, that means at least 3 months without new software and real engagement.
- An increase in the complexity of the regression tests **eventually** requiring an increase in the time spent doing Hardening Sprints – As the code base grows, so do the number of test cases. Eventually, one Sprint isn’t enough to run them all (let alone fix the defects) so we schedule another Hardening Sprint.
- More difficult to tidy messes after they’re found because the code base is more fragile – Lacking good unit tests and automated acceptance tests, making changes becomes harder because we don’t know if we can trust that our change is good. Often we avoid making changes (e.g. refactoring) because the changes are “too risky.”
- Regression Test cases run by hand (or manually) being error-prone5 – We’re relying on people noticing mistakes in software that they have seen many times before. Even the most careful tester will miss things due to this form of repetition blindness, called the Observer-Expectancy Effect.6 Relying on people to do repetitive task work is error-prone and boring for the people.
If you wish to have maintainable software, then you must eliminate the Hardening Sprint. Large-Scale Scrum hints at the problem by calling anything not truly done in the Sprint as “Undone Work.”7
Typical Causes
- A belief that teams need to work faster from the start
- Focus on increasing velocity, without first focusing on quality
- A “traditional phased” approach to Scrum
- A weak or non-existent definition of “Done”
- Lack of rigorous engineering practices
- A belief that multi-Team efforts require extra integration time before they’re ready to release
- SAFe 8 recommendation (called an IP Iteration)
Solutions
- Improve Definition of Done
- Large-Scale Scrum calls the difference between Potentially Shippable and Definition of Done “Undone Work.”9
- Improve Engineering Practices
Both of the above should result in the Team discovering Agile Test Engineering Practices such as Behaviour Driven Development (aka BDD) Specification By Example/BDD/ATDD, etc. (see: Example Mapping)
- Slow down. Don’t focus on speed – instead, focus on quality. (Which should result in the team focus of learning. This should, in turn, discover Agile Test Engineering Practices.)
- Consider the Pattern: Good Housekeeping or Daily Clean Code
- Deliver working software at the end of every Sprint. (Which should refocus on Definition of “Done” and Agile Test Engineering Practices_._)
- Consider Pattern: Teams that Finish Early Improve Faster
Realistically, there is only one solution to the challenge that Hardening Sprints represent: reduce the number of time-demanding things that get pushed forward to be a future problem. Most of the work that is delayed to a Hardening Sprint is comprised of pieces of work that are done manually. For example, many software teams have a suite of regressions tests that require a person to execute a series of steps in the software and check the results. That takes hours of labour, so to have the resources and capacity to run these tests every Sprint, we need to reduce the overall manual load.
To reduce the number of manual tasks, a team could:
- Take one or two test cases every Sprint and find ways to automate them. It is sometimes easier to automate in the area the team is already doing feature work. Caveat: the default approach to test automation – automate the GUI 10 and watch the results – is often not effective in the long run. However, effective test automation is beyond the scope of this blog entry.
- Slow down. Since automated testing will require new skills, the team needs to slow down and take time to learn. Too often, it is assumed that team members will learn by osmosis.
- Prioritize fixing defects. Delaying the fix just increases the complexity of the eventual fix and the code base. If instead, the Product Owner puts defects at the top of the Product Backlog when they’re found, they’re also sending the team a clear message: focus on quality. Related to defects are those messes (incorrectly called “Technical Debt”11) in the code base that are below the level that the Product Owner can see. If they’re small (e.g. 15-30 minutes work) they should just be fixed right away. If they’re larger, they warrant a discussion with the team on how that section of the code can be improved as part of their ongoing work.
Teams that follow this approach well should not only eliminate their Hardening Sprint, but they should also be able to join the groups that do true Continuous Deployment/Delivery.
If done correctly, Teams will eventually wander into the realm of DevOps simply by getting more truly done every Sprint.
One client started to get so good at this that their team began to do documentation work in Sprint. They were noticing that some parts of their product were hard to explain, so they took that as a hint and reworked the software to be easier to use, rather than delay and just push the problem to the future. By not postponing the problem, they delivered a higher quality product.
In Certified ScrumMaster training, when discussing the Definition of “Done”, I usually reveal my true feelings and call Hardening Sprints what they should be called: an abomination. Or a slightly gentler version: Hangover Sprints.
Do you want to coach your team towards better solutions?
Fundamentally changing the way a Team works as it transitions to practicing Scrum is one of the more challenging issues of developing high-performance teams. If you would like to learn how to handle issues that organizations face like this one in their Scrum evolution, consider attending one of our workshops, where you’ll receive hands-on learning of the challenges – and solutions – and tips on how to integrate them into your Scrum.
Related Blog Entries
Image attribution: Agile Pain Relief Consulting (Updated: March 2025)
Footnotes
-
An anti-pattern is a common response to a recurring problem that is usually ineffective and risks being highly counterproductive. ~ Wikipedia ↩
-
In the worst cases they may even be ignorant of the need to tidy up. ↩
-
It isn’t Technical Debt as originally defined by Ward Cunningham. See: https://www.ronjeffries.com/articles/019-01ff/tech-debt/ - Cunningham’s Technical Debt was intended to be a design tradeoff intentionally done now, allowing the team to finish work faster, with the intention of returning later to fix the debt. Most use of the term today should be called Technical Mess or Spaghetti. ↩
-
This isn’t explicitly part of the Negatively Reinforcing Feedback Loop image since Hardening Sprints and Manual Regression Testing are two sides of the same coin. Teams use Manual Regression test suites that grow ever longer, which delay that testing until the Hardening Sprint, and so begins another cycle. ↩
-
IP Iteration or Innovation and Planning Iteration as described: https://www.scaledagileframework.com/innovation-and-planning-iteration/ and as illustrated in the big SAFe Picture https://www.scaledagileframework.com/ - in this picture they’re illustrated after every 4 normal Sprints. ↩

Mark Levison
Mark Levison has been helping Scrum teams and organizations with Agile, Scrum and Kanban style approaches since 2001. From certified scrum master training to custom Agile courses, he has helped well over 8,000 individuals, earning him respect and top rated reviews as one of the pioneers within the industry, as well as a raft of certifications from the ScrumAlliance. Mark has been a speaker at various Agile Conferences for more than 20 years, and is a published Scrum author with eBooks as well as articles on InfoQ.com, ScrumAlliance.org and AgileAlliance.org.



